


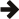
union_(),
intersect(),
and except()
build queries that produce a set-theoretic combination (union, intersection,
or set difference) of the outputs of two other queries. union_all(), intersect_all(), and except_all() are similar, but they preserve repetition
of elements. These six methods are wrappers for SQL's UNION,
INTERSECT, and EXCEPT, with and without
ALL.
(union_ is not a typo.
That identifier wears an underscore on purpose, to avoid being mistaken
for a C++ keyword.)
You can call any of:
l.union_(r)
l.intersect(r)
l.except(r)
l.union_all(r)
l.intersect_all(r) (PostgreSQL only)
l.except_all(r) (PostgreSQL only)
provided that l and r
are queries, and they have the same value type as each other.
The result is a query with
the following characteristics:
l's value
type (which is the same as r's).
l's value
mapper (which may or may not be identical to r's).
l and r:
l.union_(r) produces exactly one copy of
any output that is produced at least once by l
or at least once by r.
l.intersect(r) produces exactly one copy of
any output that is produced at least once by l
and at least once by r.
l.except(r) produces exactly one copy of
any output that is produced at least once by l
but not at all by r.
l.union_all(r) produces n+m
copies of any output that is produced n
times by l and m
times by r.
l.intersect_all(r) produces min(n,
m) copies of any output that is produced
n times by l
and m times by r.
l.except_all(r) produces max(n
- m, 0) copies of any output that is produced
n times by l
and m times by r.
This:
points.where(points->x > 4.0f) .intersect( points.where(points->y < 3.0f) )
is equivalent to this:
points.where(points->x > 4.0f && points->y < 3.0f)
Quince knows that it's equivalent, and if you write the former it will
replace it internally with the latter, to avoid SQL's INTERSECT.
In general, quince replaces set-theoretic operations by logic operations
inside a where(...) clause whenever it can prove that this
won't affect the output. It applies a fairly complex set of criteria, and
I won't attempt to describe them all, but it's useful to know the following:
If q is a query that cannot produce duplicate
outputs (which is the case if q is a table,
or is formed without any operations that can lead to duplicate outputs,
such as union_all(),
or a narrowing select()),
then quince will make the following optimizations to queries involving
q:
|
Before |
After |
|---|---|
|
|
|
|
|
|
|
|
|
Suppose you want to filter a query q by some
complex condition. Suppose that various parts of the condition depend on
domain knowledge that belongs to disparate parts of your application. Then
the obvious solution is to let the disparate application modules build
their own predicates, which
you then combine with logic operators in some way, to make one big predicate
that you pass to q.where(...).
The trouble with that approach is that it's prone to visibility
errors. The code that builds the partial predicates is sited far from the
context (q.where(...)) that makes mappers visible, so it's hard
to check that those predicates are using the mappers they're supposed to
be using.
Set-theoretic operations provide an alternative. Instead of disparate modules
building their own predicates,
let them build their own querys,
of the form q.where(...). So, when these modules are being written,
the visibility-making context is right there on the spot. Then you can
collect those specialized queries and combine them into one big query, using the set-theoretic operations.
Of course you could do that without the optimizations, but the performance impact might make you think twice about it. With the optimizations, there is no need to hesitate.